Jak definiujemy (nie)sprawiedliwość algorytmów? Bezprecedensowo rozwiązania oparte o algorytmy uczenia maszynowego i sztuczną inteligencję przenikają do codziennego wykorzystania. Zarówno firmy, jak i poszczególne osoby, często nawet nieświadomie, wykorzystują bądź są narażeni na działanie AI. Wchodząc na nasze ulubione platformy e-commerce, przeglądając Internet, składając wniosek o kredyt, bądź aplikując o pracę, coraz częściej (i stawiam tezę, że trend ten będzie utrzymywany) będziemy wyeksponowani na działanie metod, które zbiorczo nazywamy – AI.
Przyczyn tego stanu rzeczy jest kilka:
- wymogi regulacyjne związane z przetwarzaniem danych klientów; przykładem może być Ustawa Prawo bankowe art. 105a wskazujący, że: “[…] w celu oceny zdolności kredytowej i analizy ryzyka kredytowego podejmować decyzje, opierając się wyłącznie na zautomatyzowanym przetwarzaniu”; przy okazji, dokładnie ten sam artykuł wskazuje na konieczność udzielenia stosownych wyjaśnień co do podstaw podjętej decyzji,
- rosnąca jakość predykcyjna modeli uczenia maszynowego; w przypadku automatycznych modeli decyzyjnych (czy wyświetlić reklamę produktu ABC? czy zatrudni tego kandydata?) modele te uzyskuj lepsze “wyniki” niż decyzje podejmowane przez człowieka,
- zwiększenie przepustowości procesu decyzyjnego; automatyczne modele decyzyjne są w stanie generować decyzje nieporównywalnie szybciej niż człowiek; w skrajnych przypadkach obecnie funkcjonujące procesy nie mogłyby być realizowane przez ludzi, ze względu na tak duża liczbę wymaganych decyzji do podjęcia (np. modele rekomendacji produktów na stronach internetowych sklepów),
- obiektywność realizowanego procesu; mając na względzie częsty kontekst społeczny podejmowanej decyzji (czy udzielić kredytu? czy zatrudnić?), próbujemy „obiektywizować” działanie procedury, poprzez włącznie bezuczuciowego, obiektywnego sędziego jakim jest model AI.
Co do trzech pierwszych argumentów, jesteśmy raczej przekonani o ich oczywistości, o tyle obiektywizm działania samych algorytmów może być szerzej dyskutowany…
Przykład bankowy nr 1
Przyjmijmy, że istnieje bank: Daniel’s bank. Jest to bank działający na jednym, konkretnym rynku, i jak każdy bank uniwersalny, żyje z: 1) przyjmowania depozytów, i 2) udzielania kredytów. Pomińmy na potrzeby tego przykłady, że bank może również, m.in., handlować derywatami, pełnić rolę market makera, bądź świadczyć usługi dla dużych klientów korporacyjnych.
Nasz Daniel’s bank przyjął w danym okresie – np. styczeń 2022 r. - $X = 400$ aplikacji kredytowych mężczyzn (słownie: $400$ mężczyzn złożyło wnioski kredytowe, np. na kartę kredytową), oraz $Y = 100$ aplikacji kredytowych kobiet. Czyli bank otrzymał łącznie $500$ aplikacji kredytowych, i musi się zastanowić komu kredyty przydzielić, a komu nie.
Daniel’s bank działa w reżimie prawa bankowego, tj. musi się stosować do art. 105a Ustawy Prawo Bankowe: aplikacje kredytowe są zatem ocenianie w sposób automatyczny, przez przygotowany przez analityka model oceny zdolności kredytowej.
Załóżmy teraz, że bank ten wydał dla $X_+ = 200$ mężczyzn, i dla $Y_+=20$ kobiet pozytywną decyzję kredytową. To znaczy, że łącznie bank udzielił w styczniu 2022 r. $200+20=220$ kredytów. Zakładając, że wniosków kredytowych było łącznie $400+100=500$, możemy wykazać, że wskaźnik akceptacji kredytów w banku wyniósł $\frac{220}{500} = 44\%$. Wartość ta zbliżona jest z realiami kredytowymi kredytów gotówkowych w Polsce.
Czy takie działanie modelu nazwiemy działaniem sprawiedliwym? Równym dla kobiet i mężczyzn?
Pytaniem dodatkowym jest to, czy bank powinien różnicować aplikacje kredytowe ze względu na płeć? Jeżeli zmienna płeć jest zmienną prawnie chronioną (tj. prawnie zabronionym jest różnicowanie klientów ze względu na tę zmienną), a tak w większości (o ile nie we wszystkich) jurysdykcjach jest, to różnica w we wskaźniku akceptacji (dla mężczyzn $\frac{200}{400}=50\%$, dla kobiet $ \frac{20}{100}=20%$) będzie odbierana jako dyskryminacja w dostępie do usług finansowych.
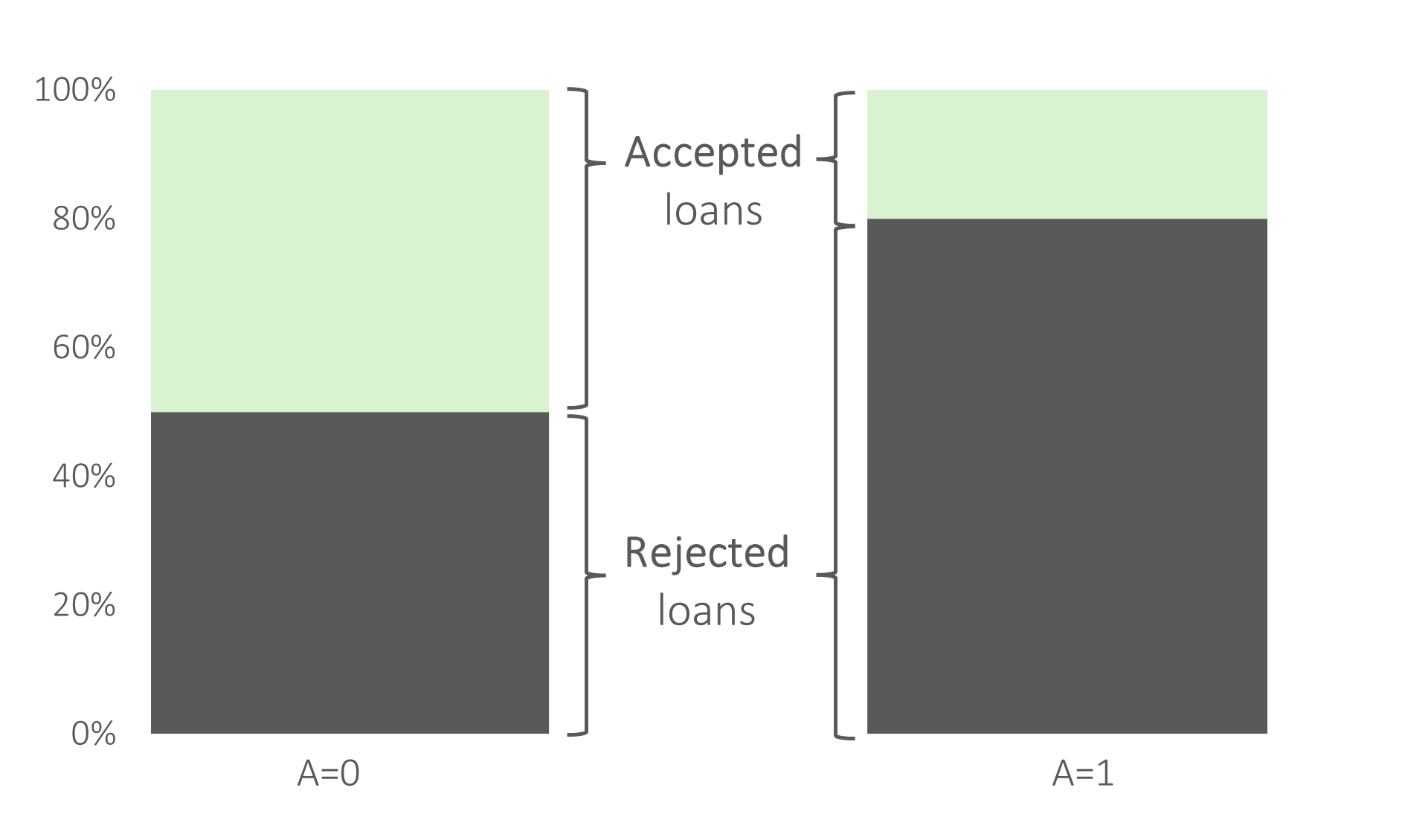
Argumentem na brak sprawiedliwego charakteru działania modelu oceny zdolności kredytowej jest odmienny wpływ jaki model ma na poszczególne grupy społeczne, tj. dla losowo wybranego mężczyzny, który złożył aplikację kredytową, można przyjąć, że prawdopodobieństwo udzielenia kredytu przez bank ABC wynosi $50\%$; dla kobiety taki model przyznaje tylko $20\%$ prawdopodobieństwo. Można zatem wskazać, że bycie mężczyzną jest niejako premiowane przez bank. Zwrócić można jednocześnie uwagę, że w tym przypadku nie wskazuje się na fakt, czy płeć jako atrybut chroniony ma realny wpływ na zdolność kredytową. Mówimy tutaj zarówno o: a) statystycznym wpływie zmiennej płeć na ocenę do spłaty zobowiązań kredytowych, jak również b) fakcie, że zmienna płeć może być dobrym proxy zmiennych socjo-demograficznych, które realnie wpływają na ocenę zdolności kredytowej.
W przypadku, gdy płeć jak i inne atrybuty chronione (np. wiek, pochodzenie etniczne) mają statystyczny wpływ na zdolność do spłaty zobowiązań kredytowych, rodzi się pytane, czy tych cech nie powinno się włączyć do modelu jako zmienne objaśniające. Należy równocześnie przytoczyć wątek już wcześniej poruszony, tj. Ustawa Prawo Bankowe w art. 70a wskazuje jednoznacznie, że „[…] na wniosek osoby fizycznej, prawnej lub jednostki organizacyjnej niemającej osobowości prawnej, o ile posiada zdolność prawną, ubiegającej się o kredyt przekazują, w formie pisemnej, [bank skład] wyjaśnienie dotyczące dokonanej przez siebie oceny zdolności kredytowej wnioskującego”. Wyjaśnienie jakie tutaj wskazano powinno obejmować informacje na temat czynników, w tym danych osobowych wnioskującego, które miały wpływ na dokonaną ocenę zdolności kredytowej.
Oznaczałoby to, że gdyby bank jako jednostka zobowiązana do przedstawienia osobom ubiegającym się o kredyt informacji (w nawiązaniu do wcześniej złożonego wniosku o taką informację), o czynnikach które miały wpływ na dokonaną ocenę zdolności kredytowej, w przypadku wniosków kredytowych musiałby wskazać wpływ czynników związanych ze zmiennymi chronionymi (np. płeć, pochodzenie etniczne). W przypadku takiej interpretacji stanu prawnego, dla wskazanego przykładu banku ABC, kobieta, która posiada wartości pozostałych atrybutów takich samych jak przykładowy inny mężczyzna, mogłaby otrzymać informację, że został jej odmówiony kredyt, ze względu na jej płeć.
Taki stan rzeczy kłuci się z prawem antydyskryminacyjnym, który jednoznacznie wskazuje, że płeć nie może być czynnikiem determinującym (nawet nie w roli głównego czynnika) decyzję o zdolności kredytowej.
Czy ten stan byłby „naprawiony” gdyby Daniel’s bank udzielał równym proporcjom akceptacji kredytowych?
Przykład bankowy nr 2
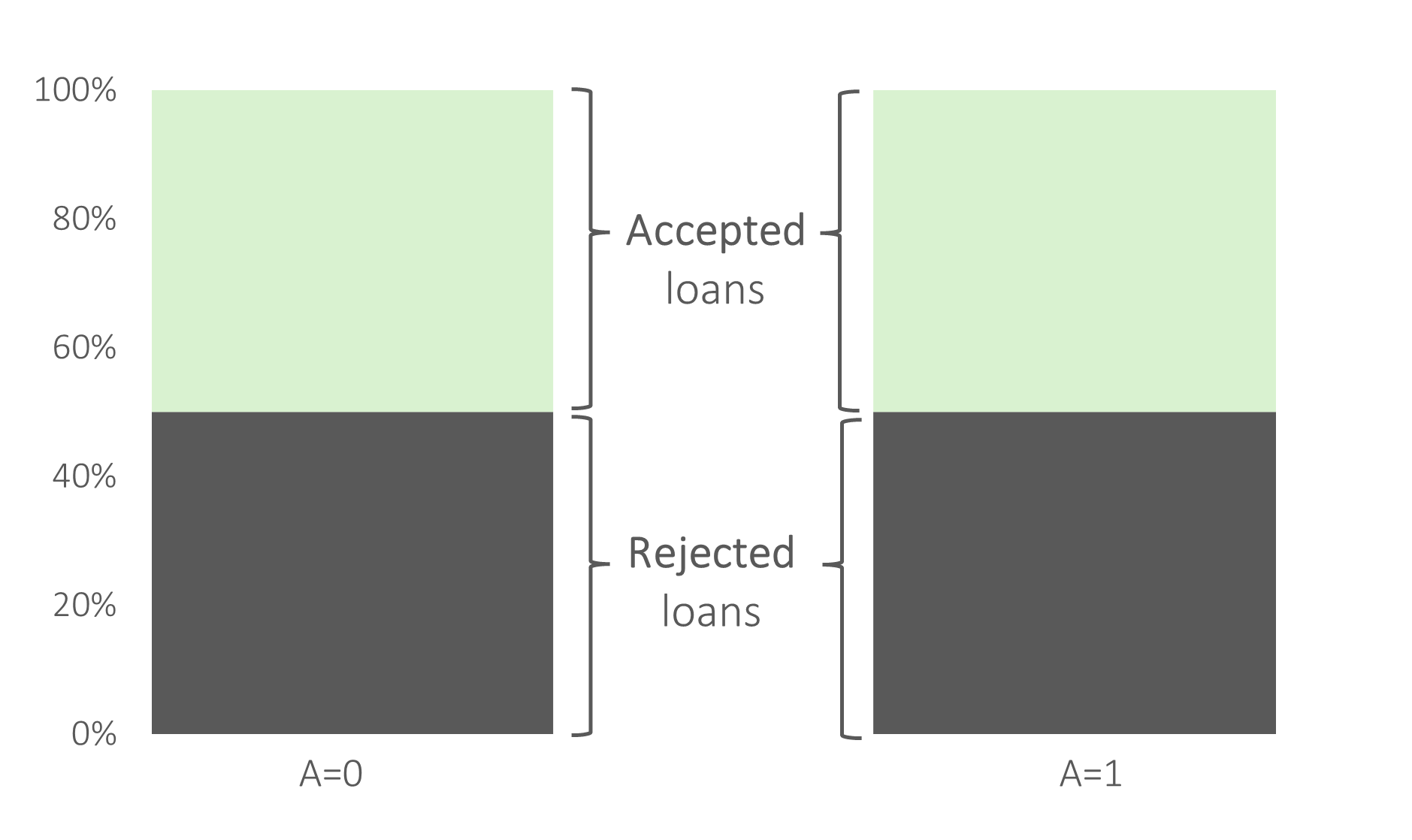
Przyjmijmy, że poziom akceptacji kredytów jest zbliżony dla obu grup wniosków $X$ i $Y$ (np. równo po $50\%$).
Przyjmijmy równocześnie, że wnioski mężczyzn są analizowane przez model typu wizard (tj. model idealny z perspektywy oceny zdolności kredytowej – tj. poziom błędów klasyfikacji dla mężczyzn jest równy 0). Z drugiej strony załóżmy również, że wnioski kobiet są rozważane przy pomoc modelu losowego - rzutu monetą…
Naturalną konsekwencją stosowania odmiennie jakościowego modelu dla dwóch podpopulacji, jest różna jakość predykcyjna działania modelu. Jakość ta, może być wyrażona np. poziomami błędów prognozy jakie generuje model: ilu klientów, którym daliśmy kredyt, nie spłaciło go? Ilu klientów, którzy kredytu nie dostali, by go spłaciło? Wnioskowanie o tej drugiej próbie może być utrudnione (wszak nie zaobserwujemy spłacalności kredytów przez klientów, którzy tego kredytu nie otrzymało), ale dla porządku dalszego wywodu przyjmijmy, że analizę tą robimy na zbiorach uczącym lub testowym – dla tych zbiorów znana jest wartość zmiennej celu (czy klient spłacił kredyt).
Taki model byłby sprawiedliwy ze względu na wpływ oddziaływania modelu na poszczególne pod populacje wnioskodawców – dokładnie $50\%$ wniosków $X$ i wniosków $Y$ otrzymało pozytywną decyzje kredytową. Ale wnioski $X$ są oceniane przy pomocy modelu doskonałego, a wnioski $Y$ są oceniane przy pomoc modelu losowego. Taki scenariusz odnosi się do odmiennego traktowania poszczególnych osób różnej płci.
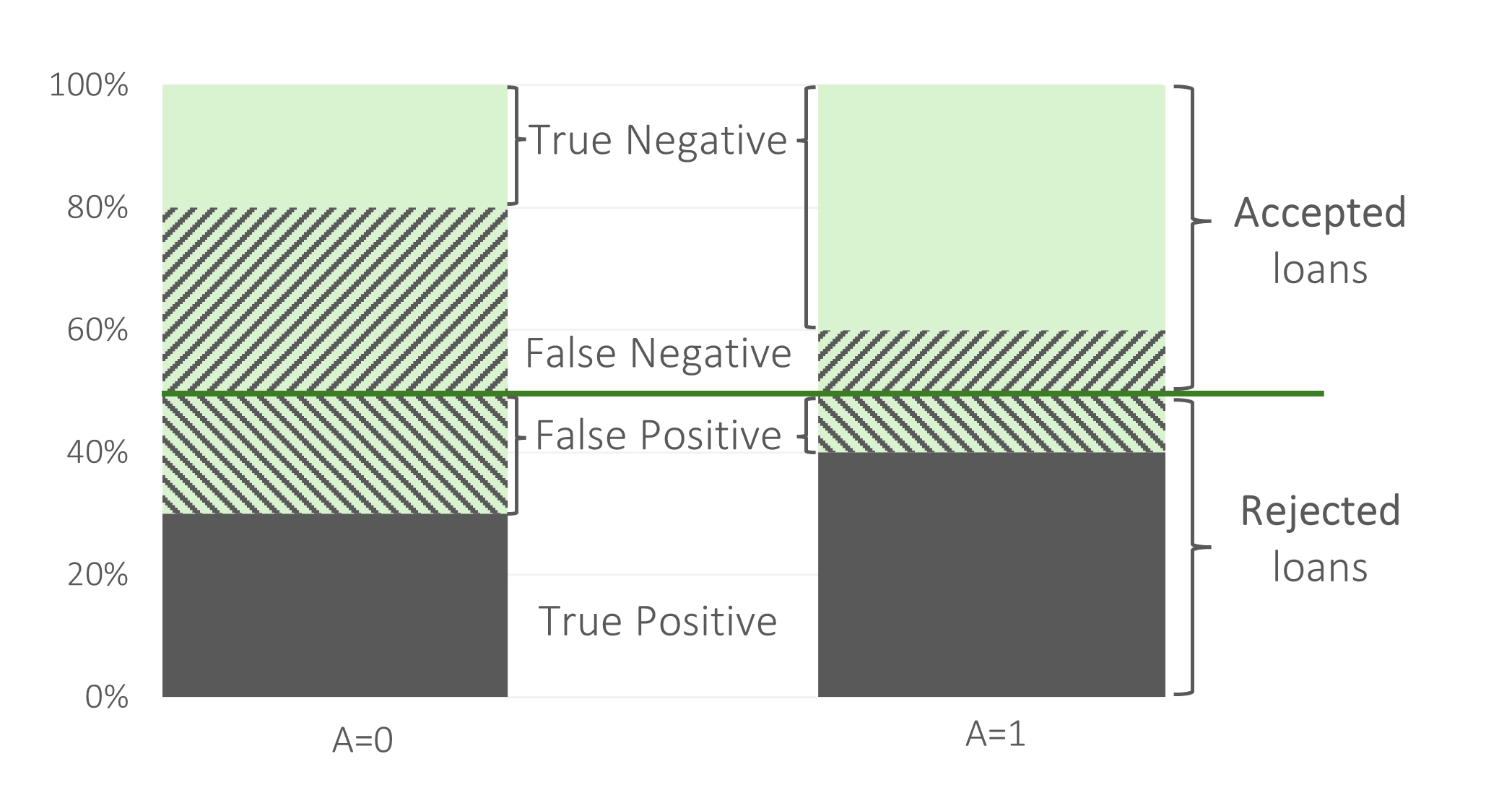
Podpopulacja kobiet jest narażona na niską jakość działania modelu oceny zdolności kredytowej: kobiet, które faktycznie nie posiadają zdolności kredytowej, mają wysokie prawdopodobieństwo mylnie uzyskać wysoką ocenę zdolności kredytowej (i tym samym pozytywną decyzję kredytową). Literatura przedmiotu wskazuje, że to właśnie błędne działania modelu, w szczególności udzielanie finansowania osobie, która nie ma zdolności do spłaty tego zobowiązania jest niebezpiecznie, zarówno z perspektywy banku jak również mikroekonomicznej – tj. pojedynczej osoby, która otrzymała kredyt.
Przykład ten pokazuje definicje równość w kontekście równości szans, lub inaczej nazywanej równości możliwości. Jako moralnie niedopuszczalne traktujemy sytuacje, w których osoby o jednakowych predyspozycjach psycho-fizycznych, są w odmienny sposób traktowane przez określoną procedurę/model, ze względu wartość atrybuty chronionego (np. na płeć lub wiek).
Powyższe dwa warianty scenariusze miały na celu wskazanie różnice w podejściach do definicji równości w kontekście oceny zdolności kredytowej. Jedno z tych podejść odnosi się do pojęcia równego wpływu przewidzianego przez regulacje. Drugi scenariusz wskazuje na model, który pomimo równego wpływu charakteryzuje się odmiennym traktowaniem poszczególnych grup płci.
Problem stronniczości algorytmicznej
Z racji wykorzystywania modeli opartych o metody uczenia maszynowego coraz częściej podmioty gospodarcze, w tym banki, napotykają na problem tzw. stronniczości algorytmicznej. Wykorzystanie modeli decyzyjnych charakteryzujących się stronniczością algorytmiczną niesie negatywne konsekwencja zarówno dla podmiotu gospodarczego korzystającego z takiego modelu, jak również klientów i poszczególnych osób wchodzących w interakcję z tym modelem: np. model oceny zdolności kredytowej i potencjalni klienci będący oceniani przez ten model. Problem stronniczości algorytmicznej związany jest z sytuacją, gdy wyniki pochodzące z modelu decyzyjnego (np. modelu oceny zdolności kredytowej) dyskryminują jednostkę lub grupę osób bez uzasadnionego przesłania dla takiego – nierównego – traktowania.
Źródła stronniczości algorytmicznej
Wyróżnia się kilka głównych przyczyn obciążenia typu stronniczości algorytmicznej, które w efekcie prowadzą do dyskryminujących poszczególne grup społecznych grupy społeczne wyników działania modeli oceny zdolności kredytowej:
- Stronniczość występująca w danych historycznych – dane, na jakich budowane są modele uczenia nadzorowanego mogą posiadać silne niezbalansowanie próby względem dyskryminowanej grupy społecznej (np. niska liczba kobiet którym historycznie udzielono kredytów). W przypadku, gdy rozkład zmiennej chronionej jest skośny, model oceny zdolności kredytowej, estymowany w oparciu o minimalizację funkcję błędu prognozy będzie charakteryzować się stronniczością algorytmiczną dla populacji o mniejszej liczbie obserwacji.
- Obciążenie pochodzące z procesu zbierania danych -– w przypadku gdy w trakcie procesu zbierania danych zachodzą systematyczne błędy lub selekcja obserwacji (tzw. błąd przeżywalności, ang. survivorship bias), trenowane na takich zbiorach danych modele będą odtwarzały tego rodzaju błędy. Istotność tego zagadnienia jest wysoka, ze względu na fakt coraz częstszego wykorzystywania alternatywnych źródeł danych (np. historia przeglądarki internetowej, informacje o korzystaniu z urządzeń mobilnych). Literatura przedmiotu$^1$ przedstawia wyzwania związane z wykorzystaniem alternatywnych źródeł danych w kontekście oceny zdolności kredytowej. Alternatywne zmienne będące tzw. \emph{digital footprint} posiadają wysoką moc predykcyjną, lecz w większości były istotnie skorelowane ze zmiennymi /atrybutami chronionymi (np. wykorzystanie atrybutu stan cywilny kredytobiorcy, jako zmiennej wysoce skorelowanej ze zmiennymi chronionymi$^2$).
- Niepoprawne przypisanie etykiet obserwacji -– problem obciążoności wynikającej z niepoprawnego przypisania etykiet (tj. wartości zmiennej celu) jest przyczyną występowania stronniczości algorytmicznej$^3$. Wartości zmiennej celu, w przypadku oceny zdolności kredytowej są to etykiety dobrego/złego klient, są budowane w oparciu o kryteria ilościowe (np. próg liczby dni opóźnienia – tzw. Days Past Due, DPD –- na poziomie 180 dni), oraz jakościowych (np. informacja czy klient jest na liście obserwowanych klientów, czy branża w której pracuje klient nie jest zagrożona). Wybór wartości progowych dla kryteriów ilościowych oraz jakościowych jest podyktowany zarówno wewnętrzną polityką instytucji finansowej (tj. poziomem apetytu i tolerancji na ryzyko kredytowej) lub zewnętrznymi regulacjami prawnymi. Zagadnienie niepopranych etykiet zmiennej celu w kontekście oceny zdolności kredytowej jest tym wyraźniejsze, ponieważ dane historyczne wykorzystywane do treningu modeli są danymi o kredytach historycznie udzielonych. Podczas szacowania modeli oceny zdolności kredytowej nie wykorzystuje wprost danych o aplikacjach kredytowych, które historycznie nie uzyskały pozytywnej decyzji kredytowej. Wartości zmiennych objaśnianych dla klientów są tylko wykorzystywane ze zbioru klientów, którzy otrzymali kredyt (tj. grupa dobrych klientów, którzy otrzymali negatywną decyzję kredytową nie jest brana pod uwagę na etapie estymacji parametrów modelu).
- Występowanie wysokiej wartości korelacji pozostałych zmiennych egzogenicznych z atrybutami chronionymi –- w przypadku automatycznych procesów analizy, budowy i utrzymania modeli decyzyjnych, zachodzi ryzyko włączenia do modelu zmiennej wysoce skorelowanej ze zmienną chronioną (np. kolor skóry oraz kod pocztowy – przykład relewantny dla kontekstu społecznego Stanów Zjednoczonych Ameryki Północnej). Wyłączenie atrybutu chronionego (nazywane czasami Fairness through Unawareness lub Fairness through Blindness), przy jednoczesnym zachowaniu wysoce skorelowanych innych zmiennych egzogenicznych, prowadzi do algorytmicznej stronniczości, tj. włączone zmienne egzogeniczne przybliżają wartość atrybutu chronionego$^4$.
- Brak bezpośredniej możliwości interpretacji wartości parametrów modelu –- w większości modele uczenia maszynowego są modelami nieparametrycznymi, nieposiadającymi bezpośredniej interpretacji parametrów, w przeciwieństwie do modeli parametrycznych – np. model regresji logistycznej. Brak możliwości prostej weryfikacji parametrów modelu decyzyjnego utrudnia analizę występowania obciążenia, a~w~efekcie uniemożliwić korektę lub reakcję ekspercką analityka tworzącego model.
$^1$ Patrz: Berg, T., Burg, V., Gombović, A. and Puri, M., 2020. On the rise of fintechs: Credit scoring using digital footprints. The Review of Financial Studies, 33(7), pp.2845-2897.
$^2$ Patrz: Klein, A., 2019. Credit Denial in the Age of AI.
$^3$ Patrz:Corbett-Davies, S. and Goel, S., 2018. The measure and mismeasure of fairness: A critical review of fair machine learning. arXiv preprint arXiv:1808.00023.
$^4$ Patrz: Hooker, S., 2021. Moving beyond “algorithmic bias is a data problem”. Patterns, 2(4).