Jakie modele ekonometryczne budować? Czy alternatywą do budowy złożonych modeli uczenia maszynowego są prace inżynierii danych?
Budując modele prognostyczne, często mamy skłonność do wykorzystywania współczesnych technik modelarskich, które umożliwiają na uzyskiwanie lepszego dopasowania do danych rzeczywistych, a co za tym idzie – uzyskiwania dokładniejszych prognoz. Dokładność ta jest przypisywana przede wszystkim automatyzacji procesu inżynierii danych – feature-enginnering – tj. procesu generowania nowych, lepszych zmiennych predykcyjnych.
Czy jednak faktycznie jest tak, że współczesne modele prognostyczne – modele uczenia maszynowego– umożliwiają na uzyskanie dodatkowej dokładności prognoz, które są poza ramami działania modeli klasycznych? Porównanie w tym miejscu do modeli klasycznych ma na celu zestawienie nowych, wciąż jeszcze nieosadzonych w pełni w praktyce modeli uczenia maszynowego, z klasycznymi podejściami. Te drugie są obecnie powszechnie uznawane i wykorzystywane, zarówno ze względu na ich interpretowalność ad hoc (bezpośrednio poprzez inspekcję parametrów modelu), jak i również prostotę, intuicyjność, oraz pełną przejrzystość działania (tj. nie występuje tutaj efekt tzw. czarnej skrzynki).
Z czym możemy mieć problem wykorzystując podejścia klasyczne?
Jakość prognostyczna modeli ekonometrycznych jest mierzona błędami prognoz ex post, tzn. wydzielając próby/zbiory: treningowe, testowe (oraz czasami walidacyjne), model estymujemy na zbiorze treningowym, a jego ocenę prowadzamy na zbiorze testowym.
Jeżeli model generuje wysokie błędy prognozy (np. prognoza tego, czy dany klient spłaci kredyt), to uznajemy, że model taki ma niską dokładność działania, a tym samym niską aplikowalność do wsparcia procesów biznesowych (wyobraźmy sobie co by się działo, gdyby model losowo przyznawał wysokie i niskie oceny kredytowe…). W jaki sposób podchodzi się do zwiększania mocy prognostycznej modeli? Podejścia ekonometrii klasycznej (tj. opartej w dużej mierze na parametrycznych modelach), zakładają przeprowadzenie różnych transformacji na zmiennych, tak, żeby niejako uwzględnić w modelu np. interakcje między zmiennymi, nieliniowy wpływ zmiennych (np. model Human Capital Earnings Function Mincera$^1$), występowania obserwacji odstających lub braków danych.
Przyjmijmy jako przykład, że modelowana zmienna zależy od trzech zmiennych objaśniających. Oznacza to, że możemy utworzyć co najmniej trzy dodatkowe zmienne reprezentujące interakcje między parami zmiennych objaśniających. A co w przypadku, gdybyśmy przed tworzeniem interakcji, utworzyli kilka – powiedzmy 9 dodatkowych zmiennych – będących wielomianami trzeciego stopnia zmiennych bazowych? Wtedy liczba interakcji pomiędzy poszczególnymi zmiennymi wzrosłaby do $\frac{n*(n-1)}{2} = \frac{12*11}{2} = 66$. Przy większej liczbie zmiennych bazowych, widać, że liczba możliwych interakcji rośnie bardzo szybko (w tempie wykładniczym: $\frac{n^2-n}{2}$).
Gdyby tworzenie wszystkich interakcji i transformacji na zmiennych realizowane było przez analityka, to nie bez znaczenia pozostają kwestie: 1) czasu przygotowania takich transformacji, 2) kosztu utrzymywania nowych zmiennych, 3) monitorowania zmian wpływu poszczególnych zmiennych. Oznacza to, że w przypadku, gdyby na wejściu analityk dysponowałby np. 20 zmiennymi, to liczba zmiennych dodatkowych utworzonych na podstawie te 20 bazowych atrybutów, może bardzo szybko urosnąć do setek, a nawet tysięcy atrybutów pochodnych (np. wielomiany, interakcje, oznaczanie braków zmiennych). W największych polskich bankach liczba zmiennych wynosi nawet kilkanaście tysięcy (patrz: Kamil Stupak. W takim przypadku, do obsługi tak tworzonych tzw. tabel analitycznych (ang. Analytical Base Table), potrzeba by było całego departamentu analityki danych, oraz drugiego zespołu odpowiedzialnego za utrzymywanie jakości i spójności danych – zespołu Data Governance.
Czy stosować podejścia data- czy model-centric?
Poprzez podejścia data-centric rozumiem podejścia, w których nakład pracy analityka jest przesunięty na pracę z danymi. Tak jak wcześniej zostało wskazane – “bo wykonać mi trzeba dzieło wielkie, pilne” – pracy do wykonania w zakresie transformacji danych jest dużo; zarówno tej technicznej (tj. transformacje danych), jak i również późniejszej weryfikacji uzyskanych atrybutów z działami biznesowymi. Bardzo często samo uwarunkowanie procesu biznesowego, może skutkować pewnymi specyficznymi przypadkami (patrz przykłady od Siddiqi dot. zróżnicowania procesu oceny zdolności kredytowej w różnych instytucjach$^2$). Nurt takiego podejścia może się kojarzyć z podejściami klasycznej ekonometrii – budujemy model, patrzymy na jego własności, zaczynamy pracę z transformacjami danych, sprawdzamy wpływ zastosowanych transformacji na uzyskiwaną dokładność modelu itd.
Z drugiej strony, możemy spróbować przeciwnego podejścia: traktujemy dane jako zadane, i to nad czym analityk pracuje to budowa bardziej złożonych modeli, inherentnie uwzględniających nieliniowości, interakcje itp. Modele tej klasy – z reguły są to modele nieparametryczne – nazywane są modelami uczenia maszynowego i z racji na swoją budowę (tj. sztuczne sieci neuronowe lub modele oparte o architekturę drzew klasyfikacyjnych) umożliwiają natywne uwzględnienie złożonych relacji między zmiennymi. Podejście takie nazywać będę dalej podejściami model-centric.
Dlaczego to takie istotne?
Obecnie większość artykułów naukowych dotyczących sztucznej inteligencji, wpada zdecydowanie w nurt modelowania typu model-centric; Andrew Ng, pionier AI wskazuje, że ok. 99% badań i publikacji, jest skupiona na podejściu model-centric. Część z tych przyczyn wynika z faktu, że: a) różne zbiory danych posiadają swoiste charakterystyki (np. dane głosowe vs. zdjęcia, dane medyczne vs. finansowe), b) istnieją różne praktyki w zakresie zbierania danych (częściowo przyczyna leży w zmianach technologicznych: wyobraźmy sobie skanery medyczne współczesne i z początku roku 2000 – standardy formatów danych będą różne w przypadku), c) nie istnieje standard zapisu i reprezentacji zmiennych, oraz d) występują problemy z jakością danych (w szczególności Andrew Ng podkreśla label inconsistencies).
Przykład numeryczny – model centric approach
Wykorzystajmy dobrze znany i popularny zbiór danych Give Me Some Credit, dostępny na platformie Kaggle. Ten zbiór danych zawiera atrybuty klientów banku (np. wiek, miesięczne dochody, wykorzystanie otwartych linii kredytowych) oraz informację o tym, czy dany klient dopuścił się poważnego opóźnienia w spłacie kredytu.
Dostępny zestaw możemy opisać jako agregaty – dane są podane w zwartej formie, przedstawiają wartości zagregowane dla poszczególnych klientów. Oznacza to, że dane te były już przetwarzane wcześniej – ponieważ nie są to techniczne logi pochodzące z systemów bankowych. Dane te zawierają już zaimplementowaną logikę – np. logikę sumowania względem czasu i indeksu klienta (agregaty).
Dane te jednak zawierają również sporo: obserwacji brakujących (a jak wiemy, sama informacja o tym, że brakuje danych może być informacją predyktywną) oraz wartości odstających. Wartości atrybutów nie są w żaden sposób znormalizowane np. wielkość wynagrodzenia waha się od wartości 0 do 3,008,750. W celu oszacowania modeli obserwacje brakujące zostały usunięte; innych problemów uniemożliwiających estymację modeli nie było.
Przyjrzyjmy się zatem dwóm modelom, które moglibyśmy wyszacować dla takiego przykładu: np. Regresji Logistycznej (klasyczny model ekonometryczny), oraz Gradient Boosting (model uczenia maszynowego). Wartości przedstawione w tabeli przedstawiają średnią oraz odchylenie standardowe współczynnika Gini-ego, wyznaczone na podstawie 100 wylosowanych prób (każda próba zawierała 20 tys. obserwacji, 12 tys. w zbiorze treningowym i 8 tys. w zbiorze testowym).

Model klasyczny – Regresja Logistyczna – na danych czystych (tj. bez przetwarzania) wygenerował średni wynik współczynnika Gini-ego na poziomie 37.45%, przy czym odchylenie standardowe było na poziomie 4.62%. W porównaniu z modelem uczenia maszynowego – Gradient Boosting – średnia współczynnika Gini-ego to 70.15% przy odchyleniu standardowym równym 1.86% – wynik ten jest niezadowalający: zarówno średnia wartość Gini-ego jest niższa, jak i zmienność tego wyniku jest wyższa. Sugeruje to słabsze dopasowanie modelu Regresji Logistycznej do danych, przy towarzyszącej równocześnie niższej stabilności modelu.
Przykład numeryczny – data centric approach
Czy modele ekonometrii klasycznej pozostawały bezradne w takich sytuacjach? Ekonometrycy dysponują całym wachlarzem możliwych modyfikacji i transformacji, które można zastosować na danych wejściowych. Prosty model pozostaje bez zmian, ale przekształcamy dane, aby móc budować lepsze modele.
Przykładowymi transformacjami są:
- transformacja logarytmiczna zmiennych – często jesteśmy zainteresowani poziomami zmiennych, a nie ich konkretnymi wartościami (patrz przykład z wynagrodzeniem wyżej – nie ma aż takiego znaczenia czy zarabiamy 10,000, czy 10,001),
- binaryzacja zmiennych – w przypadku zmiennych ciągłych pomocnym może być sprowadzenie tych zmiennych
do wartości dyskretnych (np. zamiast wartości zmiennej ciągłej dot. zarobków na poziomie 13,000, otrzymujemy
zmienną binarną wskazującą na koszyk zarobków na poziomie
10,000-15,000). Binaryzacja zmiennych umożliwia również na uchwycenie nieliniowego wpływu danej zmiennej (np. wiek: osoby najmłodsze i najstarsze z reguły mają mniejszą zdolność kredytową, w przeciwieństwie do osób w średnim wieku – zmienna wiek ma ‘n’ kształtny wpływ na zdolność kredytową), - tworzenie interakcji między zmiennymi – zmienne socjodemograficzne często posiadają interakcje między sobą (występuje tutaj często efekt paradoksu Simpsona),
- tworzenie flagi obserwacji brakujących – bardzo często brak informacji/odczytu zmiennej jest również informacją; gdybyśmy budowali model oceny zdolności kredytowej i nie mielibyśmy informacji o zarobkach danego aplikanta kredytowego, to możemy spodziewać się, że wartość tego wynagrodzenia jest niska albo bardzo wysoka – oba przypadki mają wpływ na zdolność do spłaty kredytu,
- tworzenie flagi obserwacji odstających – empiryczny rozkład wartości danego atrybutu może posiadać obserwacje
odstające, tj. istotnie oddalone od pozostałego ciała rozkładu; dla przykładu w zbiorze danych Give Me Some Credit
zmienna
DebtRatioprzyjmuje typowo wartości od 0 do 1 (aż 93% obserwacji mieści się w tym zakresie).
Czy te transformacje dają nam wartość modelarską? Przekonajmy się…
Drugi eksperyment numeryczny zakłada wykorzystanie tych samych model – Regresja Logistyczna i Gradient Boosting – ale przy wykorzystaniu wzbogaconego zbioru danych, tj. zbioru danych po przeprowadzonych transformacjach. Z wyjściowych 10 zmiennych objaśniających, uzyskujemy zmiennych aż 68 (dodawanie flag binarnych, binaryzacja zmiennych itp.). Taki zbiór nazwę dalej zbiorem inżynierii cech (ang. feature engineering) – ja też nie jestem przekonany co do tego polskiego tłumaczenia…

Jak widać, na przetworzonym zbiorze jakość obu modeli wzrosła. Wzrost ten jednak był w większym zakresie widoczny w modelach klasycznych; modele tej klasy również zostały ustalbilizowane – rozkład wartości współczynnika Gini-ego charakteryzuje się niższą wariancją.
W gestii decydenta pozostaje, który model powinien zostać wykorzystany. Należy jednak wskazać na cechy każdego z 4 przedstawionych podejść:
- dane proste, model klasyczny: uzyskujemy bardzo szybko kiepskiej jakości wyniki o wysokim poziomie zmienności.
- dane proste, model złożony: uzyskujemy (prawie) docelowy poziom możliwej jakości prognoz na zbiorze testowym, niską zmienność; tracimy wytłumaczalność modeli i możliwość bezpośredniej kontroli nad jego działaniem (wyobraź sobie, że na prognozie model uzyskałby dane, które istotnie różnią się od danych zbioru treningowego…). Oszacowanie modelu złożonego jest jednak trochę bardziej kosztowne czasowo (sam proces treningu modelu, ale również faza optymalizacji hiperparametrów).
- dane przetworzone, model klasyczny: uzyskujemy odrobinę gorszy model od modelu złożonego, ale posiadamy model w pełni wytłumaczalny (tj. wytłumaczalność na poziomie ad hoc), posiadamy pełną kontrolę nad zmiennymi (tj. wiemy, co się wydarzy, gdy zaczniemy uzyskiwać zmienne o wartościach wyższych niż na zbiorze treningowym). Model taki jednak wymaga nieproporcjonalnie więcej czasu na przygotowanie danych, ich utrzymanie itp.
- dane przetworzone, model złożony: uzyskujemy jakościowo najlepszy model, przy czym jest potrzeba dużej pracy z danymi, jak i z samym modelem; jednocześnie tracimy wytłumaczalność i kontrolę nad zmiennymi (problem modelu black-box).
Próba uogólnienia podejść
Bazując na dotychczasowych rozważaniach i eksperymentach, można spróbować uogólnić je w następujący sposób.
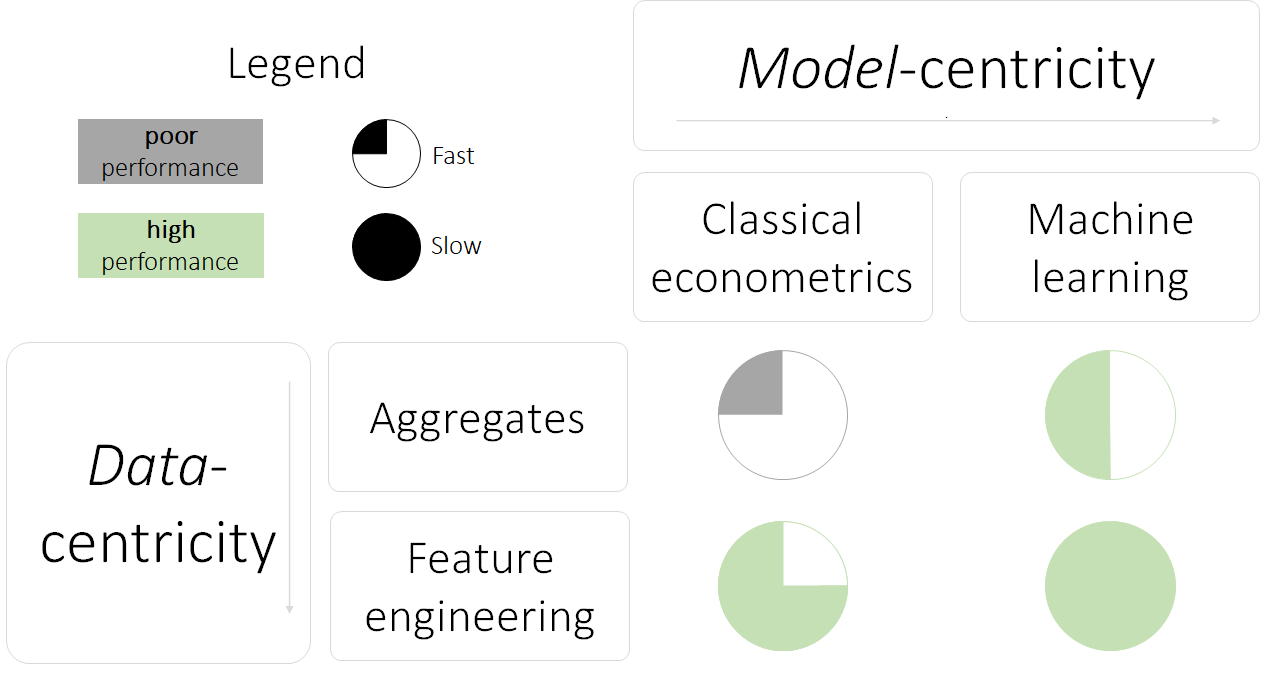
Wybierając podejście – data vs. model centric – miejmy na względzie, że wybór ten jest zawsze dokonywany w pewnym reżimie i okolicznościach. W przypadku gdy wytłumaczalność modelu jest kluczowa (np. model decyzji kredytowych), rekomendowane podejście będzie składać się z przetworzonych danych i modelu klasycznego. W przypadku gdy potrzebne jest uzyskania szybko zgrubnego oszacowania możliwości predykcyjnych na danym zbiorze danych, rekomendowanym modelem będzie model złożony na danych prostych; w przypadku, gdy głównym zagadnieniem jest jakość predykcyjna modelu, rekomenduje się podejście danych przetworzonych i złożonego modelu – podejście to jest jednak zdecydowanie najbardziej kosztowne czasowo.
$^1$Mincer, J., 1974. Schooling, Experience, and Earnings. Human Behavior & Social Institutions No. 2.
$^2$Siddiqi, N., 2017. Intelligent credit scoring: Building and implementing
better credit risk scorecards. John Wiley & Sons.